@Docs
The @Docs context provider allows you to efficiently reference documentation directly within Continue.
Enabling the @Docs context provider
To enable the @Docs context provider, add it to the list of context providers in your config.json file.
- YAML
- JSON
context:
- provider: docs
{
"contextProviders": [
{
"name": "docs"
}
]
}
How It Works
The @Docs context provider works by
- Crawling specified documentation sites
- Generating embeddings for the chunked content
- Storing the embeddings locally on your machine
- Embedding chat input to include similar documentation chunks as context
Indexing Your Own Documentation
Hub docs Blocks
@Docs uses docs blocks in Assistants from the hub. Visit the hub to explore docs blocks or create your own.
Through the @Docs Context Provider
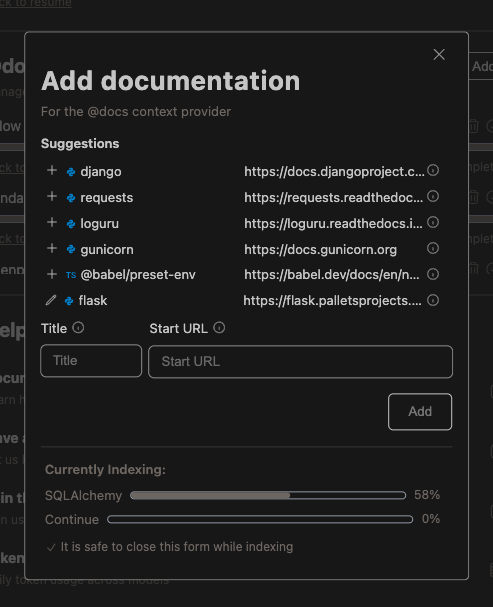
To add a single documentation site, we recommend using the Add Documentation Form within the GUI. This can be accessed
- from the
@Docscontext provider - type@Docsin the chat, hitEnter, and search forAdd Docs - from the
Morepage (three dots icon) in the@docs indexessection the@Docscontext provider.
In the Add Documentation Form, enter a Title and Start URL for the site.
Title: The name of the documentation site, used for identification in the UI.Start URL: The URL where the indexing process should begin.
Indexing will begin upon submission. Progress can be viewed in the form or later in the @docs indexes section of the More page.
Documentation sources may be suggested based on package files in your repo. This currently works for Python requirements.txt files and Node.js (Javascript/Typescript) package.json files.
- Packages with a valid documentation URL (with a
+icon) can be clicked to immediately kick off indexing - Packages with partial information (with a pen icon) can be clicked to fill the form with the available information
- Note that you can hover over the information icon to see where the package suggestion was found.
In a configuration file
For bulk documentation site adds or edits, we recommend editing your global configuration file directly. Documentation sites are stored in an array within docs in your global configuration, as follows:
- YAML
- JSON
docs:
- title: Nest.js
startUrl: https://docs.nestjs.com/
faviconUrl: https://docs.nestjs.com/favicon.ico
{
"docs": [
{
"title": "Nest.js",
"startUrl": "https://docs.nestjs.com/",
"faviconUrl": "https://docs.nestjs.com/favicon.ico"
}
]
}
See the config reference for all documentation site configuration options.
Indexing will re-sync upon saving the configuration file.
Configuration
Using Your Embeddings Provider
If you have set up an embeddings provider, @docs will use your embeddings provider. Switching embeddings providers will trigger a re-index of all documentation sites in your configuration.
Reranking
As with @Codebase context provider configuration, you can adjust the reranking behavior of the @Docs context provider with the nRetrieve, nFinal, and useReranking.
- YAML
- JSON
context:
- provider: docs
params:
nRetrieve: 25 # The number of docs to retrieve from the embeddings query
nFinal: 5 # The number of docs chunks to return IF reranking
useReranking: true # use reranking if a reranker is configured (defaults to true)
{
"contextProviders": [
{
"name": "docs",
"params": {
"nRetrieve": 25, // The number of docs to retrieve from the embeddings query
"nFinal": 5, // The number of docs chunks to return IF reranking
"useReranking": true // use reranking if a reranker is configured (defaults to true)
}
}
]
}
GitHub
The GitHub API rate limits public requests to 60 per hour. If you want to reliably index GitHub repos, you can add a github token to your config file:
- YAML
- JSON
context:
- provider: docs
params:
githubToken: <GITHUB_TOKEN>
{
"contextProviders": [
{
"name": "docs",
"params": {
"githubToken": "github_..."
}
}
]
}
Local Crawling
By default, Continue crawls documentation sites using a specialized crawling service that provides the best experience for most users and documentation sites.
If your documentation is private, you can skip the default crawler and use a local crawler instead by setting useLocalCrawling to true.
- YAML
- JSON
docs:
- title: My Private Docs
startUrl: http://10.2.1.2/docs
faviconUrl: http://10.2.1.2/docs/assets/favicon.ico,
useLocalCrawling: true
{
"docs": [
{
"title": "My Private Docs",
"startUrl": "http://10.2.1.2/docs",
"faviconUrl": "http://10.2.1.2/docs/assets/favicon.ico",
"useLocalCrawling": true
}
]
}
Chromium crawling has been deprecated
Further notes:
- If the site is only locally accessible, the default crawler will fail anyways and fall back to the local crawler.
useLocalCrawlingis especially useful if the URL itself is confidential. - For GitHub Repos this has no effect because only the GitHub Crawler will be used, and if the repo is private it can only be accessed with a priveleged GitHub token anyways.
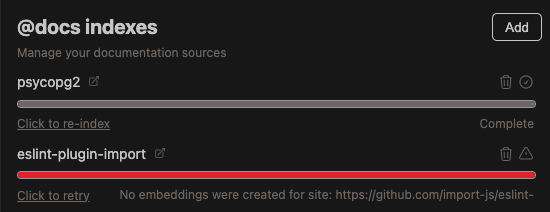
Managing your docs indexes
You can view indexing statuses and manage your documentation sites from the @docs indexes section of the More page (three dots)
- Continue does not automatically re-index your docs. Use
Click to re-indexto trigger a reindex for a specific source - While a site is indexing, click
Cancel indexingto cancel the process - Failed indexing attempts will show an error status bar and icon
- Delete a documentation site from your configuration using the trash icon
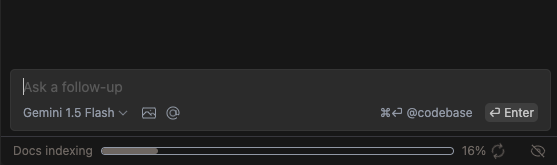
You can also view the overall status of currently indexing docs from a hideable progress bar at the bottom of the chat page
You can also use the following IDE command to force a re-index of all docs: Continue: Docs Force Re-Index.
Examples
VS Code minimal setup
The following configuration example works out of the box for VS Code. This uses the built-in embeddings provider with no reranking.
- YAML
- JSON
context:
- provider: docs
docs:
- title: Nest.js
startUrl: https://docs.nestjs.com/
{
"contextProviders": [
{
"name": "docs",
}
],
"docs": [
{
"title": "Nest.js",
"startUrl": "https://docs.nestjs.com/",
},
]
}
Jetbrains minimal setup
Here is the equivalent minimal example for Jetbrains, which requires setting up an embeddings provider.
- YAML
- JSON
models:
- name: LMStudio embedder
provider: lmstudio
model: nomic-ai/nomic-embed-text-v1.5-GGUF
roles:
- embed
context:
- provider: docs
docs:
- title: Nest.js
startUrl: https://docs.nestjs.com/
{
"contextProviders": [
{
"name": "docs",
}
],
"docs": [
{
"title": "Nest.js",
"startUrl": "https://docs.nestjs.com/",
},
],
"embeddingsProvider": {
"provider": "lmstudio",
"model": "nomic-ai/nomic-embed-text-v1.5-GGUF"
}
}
Full-power setup (VS Code or Jetbrains)
The following configuration example includes:
- Examples of both public and private documentation sources
- A custom embeddings provider
- A reranker model available, with reranking parameters customized
- A GitHub token to enable GitHub crawling
- YAML
- JSON
models:
- name: LMStudio Nomic Text
provider: lmstudio
model: nomic-ai/nomic-embed-text-v1.5-GGUF
roles:
- embed
- name: Voyage Rerank-2
provider: voyage
apiKey: <VOYAGE_API_KEY>
model: rerank-2
roles:
- rerank
context:
- provider: docs
params:
githubToken: <GITHUB_TOKEN>
nRetrieve: 25
nFinal: 5
useReranking: true
docs:
- title: Nest.js
startUrl: https://docs.nestjs.com/
- title: My Private Docs
startUrl: http://10.2.1.2/docs
faviconUrl: http://10.2.1.2/docs/assets/favicon.ico
maxDepth: 4
useLocalCrawling: true
{
"contextProviders": [
{
"name": "docs",
"params": {
"githubToken": "github_...",
"nRetrieve": 25,
"nFinal": 5,
"useReranking": true
}
}
],
"docs": [
{
"title": "Nest.js",
"startUrl": "https://docs.nestjs.com/"
},
{
"title": "My Private Docs",
"startUrl": "http://10.2.1.2/docs",
"faviconUrl": "http://10.2.1.2/docs/assets/favicon.ico",
"maxDepth": 4,
"useLocalCrawling": true
}
],
"reranker": {
"name": "voyage",
"params": {
"model": "rerank-2",
"apiKey": "<YOUR_VOYAGE_API_KEY>"
}
},
"embeddingsProvider": {
"provider": "lmstudio",
"model": "nomic-ai/nomic-embed-text-v1.5-GGUF"
}
}